


尝试基于无数据库技术实现动态网站开发的技术笔记
- 2023-05-23
- 2220
- 飞驰的心
传统的web开发数据库的重要性无需多言,但凡事总有例外——
有一个小白朋友想自己部署网站,他从网上下载了一套php的cms源码部署,就卡到数据库上了。抱怨说:“网站为啥都要数据库,没有数据库多好”。这句话一下挠到我的痒痒肉,于是我就萌生了一个想法——做一个免数据库的网站系统。
很多人对“无数据库的网站”,第一印象就是——不就是纯html的“静态网页”么?你这么理解也没错,但随着开发思想的进步迭代,有些东西还是能玩出新花样的。
所谓“无数据库网站”要解决的首要问题就是免部署数据库,使网站开箱即用。但网站毕竟还是需要更新内容的,如果让用户去编辑一个个html页面,那就不是网站系统了,而是一堆页面文件而已。
所以:我们要解决网站既不要数据库,还能让用户正常的发布和更新(修改、删除)内容。
有了这个指导思想以后,实现起来也不是特别难——
1、构建系统架构
操作者发布内容,传统的操作是将内容存入数据库,而我们现在要做的是直接将内容生成Html文件。
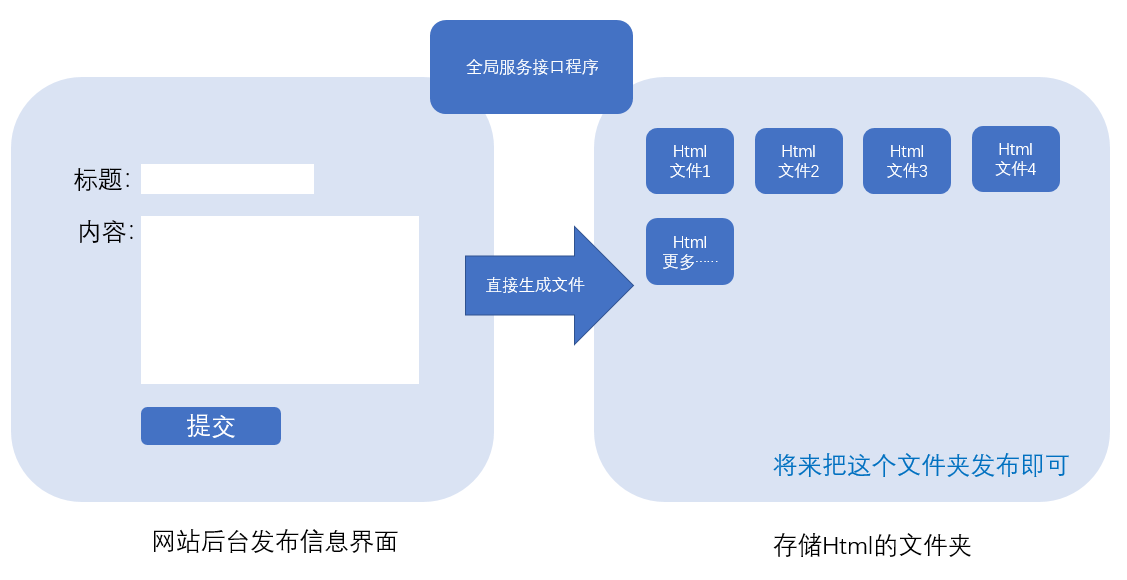
2、开发设计系统的核心:全局服务接口程序
对于这个免数据库架构的网站而言,全局接口程序相对简单,说到底就是对物理文件的读写和解析操作,这里考验程序员对组织能力的功夫。
a、生成文件
接收前端发来的数据,将数据转化为html文本,存于指定文件夹。这里需要注意——
前端发来的内容可能有图片,所以要把图片和文本分别保存。
需要提前设计一个html模板,处理文本之前,先预读模板,然后把模板中的标记替换成前端传来的文本,然后按照一定的规则保存文件,例如——
a_20230522.htm、b_20230518.htm、d_20230511.htm……
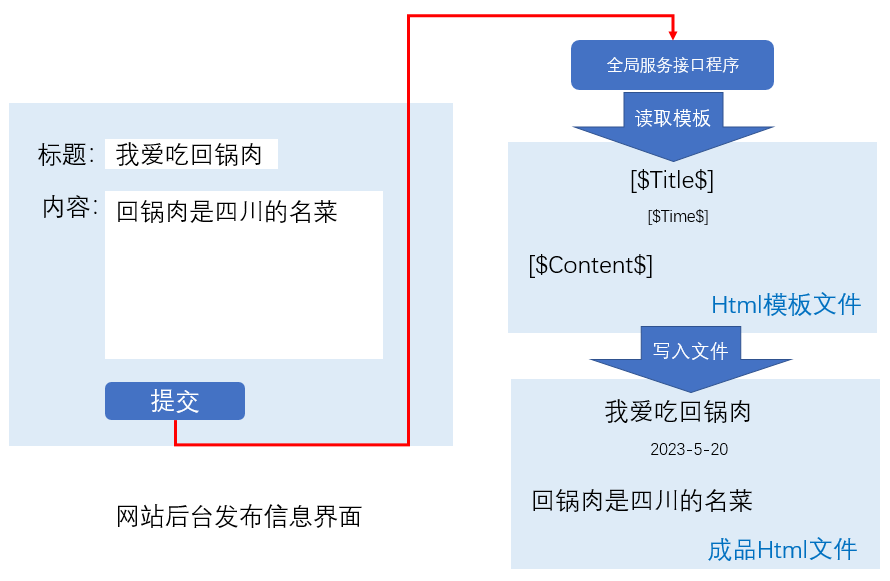
b、组织文件
假设:通过后台发布了50篇内容,那服务器上相应的就有了50个html文件,上边咱们说过保存文件的时候,文件名有一定的规则,比如——
a_23230522.htm 通过观察能够发现文件名由字母+日期构成,这时候就可以通过之前咱们设计的文件规则进行组织,如下图:
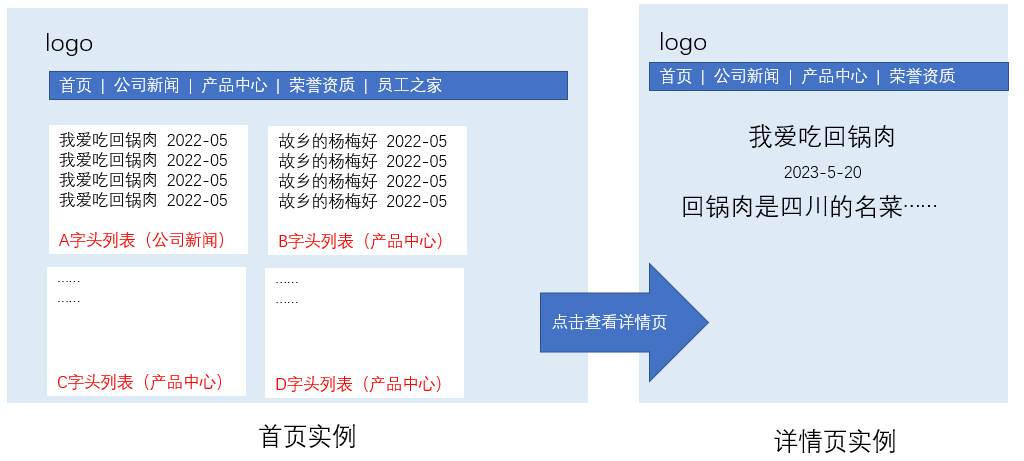
关于文件组织,这就需要在全局接口中增加一个接口方法:遍历指定文件夹下的html文件,根据文件名规则进行分类输出json列表(暂命名:fileTOjson),以供首页解析调用,无论是jqurey还是vue,请求json数据填充首页,这是前端基本功,不赘述了。
如果基于seo要求,这种请求接口的方法可以在后端进行:需要再做一个首页模板,每个列表区自定义一个版区标签,如下图——
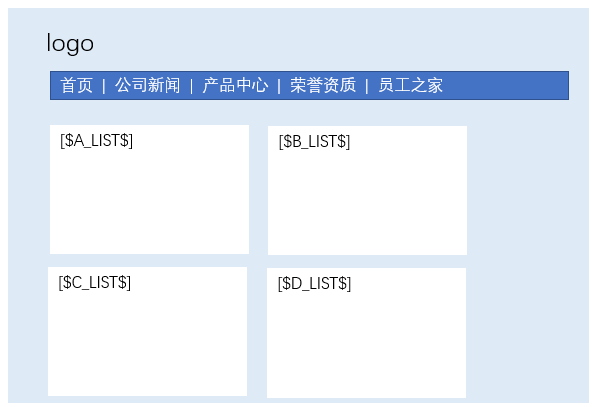
后端请求“遍历文件并输出json列表(fileTOjson)”的那个接口,得到json后,把每个字头的文件列表,替换到上图对应的版区中,然后输出htm(即动态输出了首页)。
栏目页和首页的流程类似,分页问题可以不用考虑,就算输出一个1M的json列表,也足以承载上万条内容的目录。配置再烂的服务器,都是秒处理秒完成。
C、修改文件
增删改查这是信息化领域最基本的需求,后台搞一个列表,删除不用说了吧,这里主要讲讲修改的逻辑:
传统修改内容,一般是从数据库里取信息进行修改,然后提交保存到数据库中,咱这个项目没有数据库,所以就需要直接修改html文件,如下图所示:
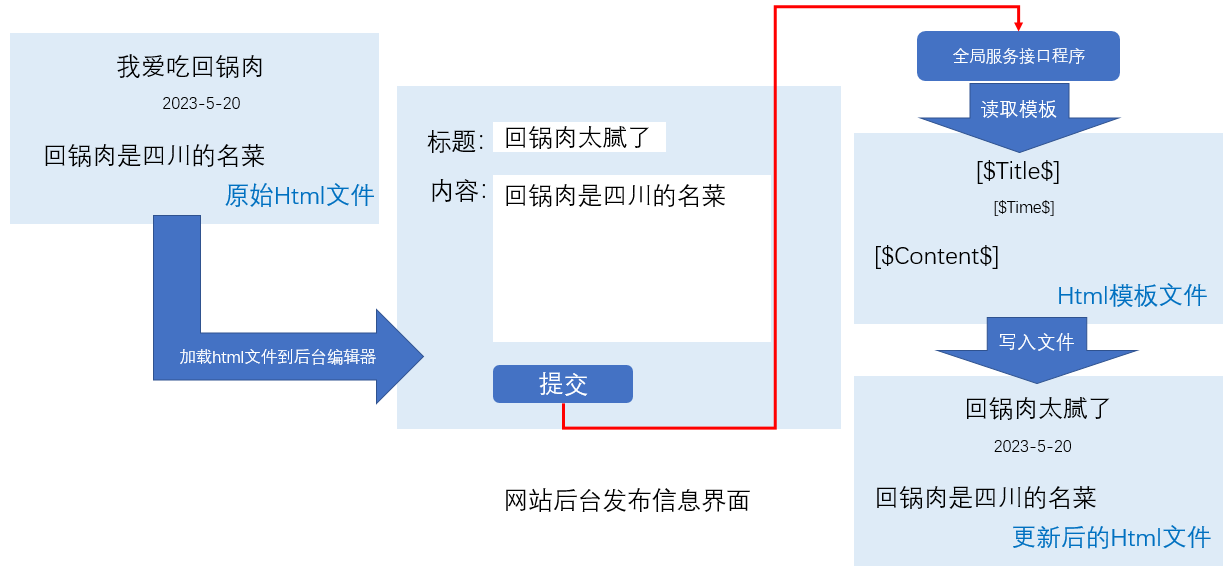
这里有个小小的技术点:从数据表字段(标题、内容)载入到编辑器的各个框里,是传统的做法。在这里你读取原始html后,其实也是相似的思路,把html的标题、内容,读入后台对应的编辑框中。方法有很多,每个语言都能很好的处理,最不济jqurey的一个$("#").text()也就把问题解决了。上面说过,咱们生成的htm都是基于模板生成的(规则很整齐),你处理自己写的模板难道还有难度?
1、读取原始html文件
2、解析原始html文件,取出:标题、内容等字段,并写入编辑器的指定位置
3、编辑器修改内容后,提交;就生成了新的html文件
现在整个技术架构相信大家已经看明白了吧,过去是对数据库的增删改查、现在改成了对文件的增删改查,这么一个架构可以有效的满足一般官网、博客、电影、音乐、图片库等文本型、资源型网站的需求。这个架构基于“文件组织”的思想构建,无论从安全性、易用性、部署的便捷性都极具优势。
一个api程序五六个接口就搞定,剩下全都是html文件,无论什么web服务器:iis、tomcat、nginx无需做任何配置就能发布。这个架构更是铜墙铁壁一般无视黑客攻击、sql注入、cookies欺骗、跨站之类的。个人觉得本架构对用户的技术依赖,已经低到会用电脑就能搞定的地步了。
当然劣势也是有的,比如:数据查询、统计就比较麻烦;搜索功能可通过接口实现全文检索,如果需要对细节数据进行统计,这就不行了。另外这种架构对爬虫“极为友好”,基本上入门级爬虫就能爬光网站所有内容,对搜索seo的影响当然是积极的,但想屏蔽私人爬虫也只能再服务器的防火墙上想办法了。
总之尺有所短寸有所长,合适的工具用在合适的领域就行。
这是我前几天花了一下午时间做的一个基于“文件组织”方法实现的电子画册,同样是不用数据库,0部署,0维护(连后台管理都没有)用户只需要把图片放入指定文件夹即可,系统自动生成缩略图、自动生成播放模板。




点开一张图片即可查看,同时后端程序可取出图片的exif信息(当然也可以编辑),如果想做一个专业的图片网站,通过这个程序实现自动化管理,可以大大节约人力成本。当然也可以做成影视、企业官网等。
通过我这些年的观察,用户对功能强大操作繁琐的程序有很大的意见,所以我这些年的开发方向一直都往极简化方面靠。
感谢阅读,希望我这点小经验,能给你以后开发起到一点启发。


评论
全部评论
共{{commentCount}}条{{rs.Msg_Content}}